Chat UI
A built-in chat interface for interactive conversations with your LLM agents, supporting rich media
📝 Rich Markdown & Syntax Highlighting
Full markdown rendering with syntax highlighting for popular programming languages:
Code blocks include:
- Copy to clipboard on hover
- Language detection
- Line numbers
- Syntax highlighting
Compact Feature
The Compact feature is a powerful tool designed to help you manage long conversations by summarizing the current thread into a more concise version. This allows you to continue your conversation with the AI while significantly reducing token usage and costs, without losing the context of your discussion.
When to use it
The Compact button appears automatically at the bottom of your thread when:
- The conversation has more than 10 messages.
- OR you have used more than 40% of the model's context limit.
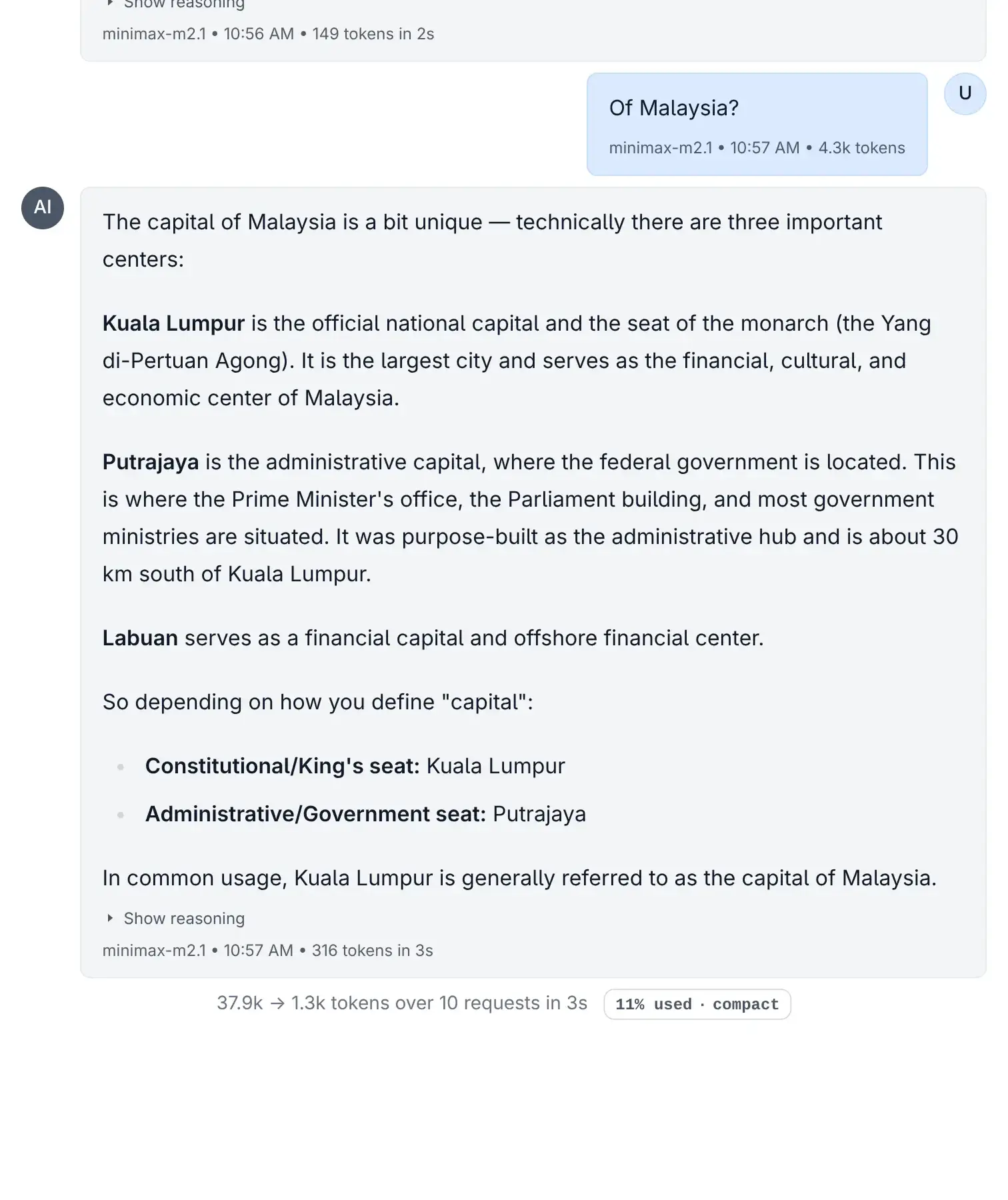
Compact Button
Click to view full size
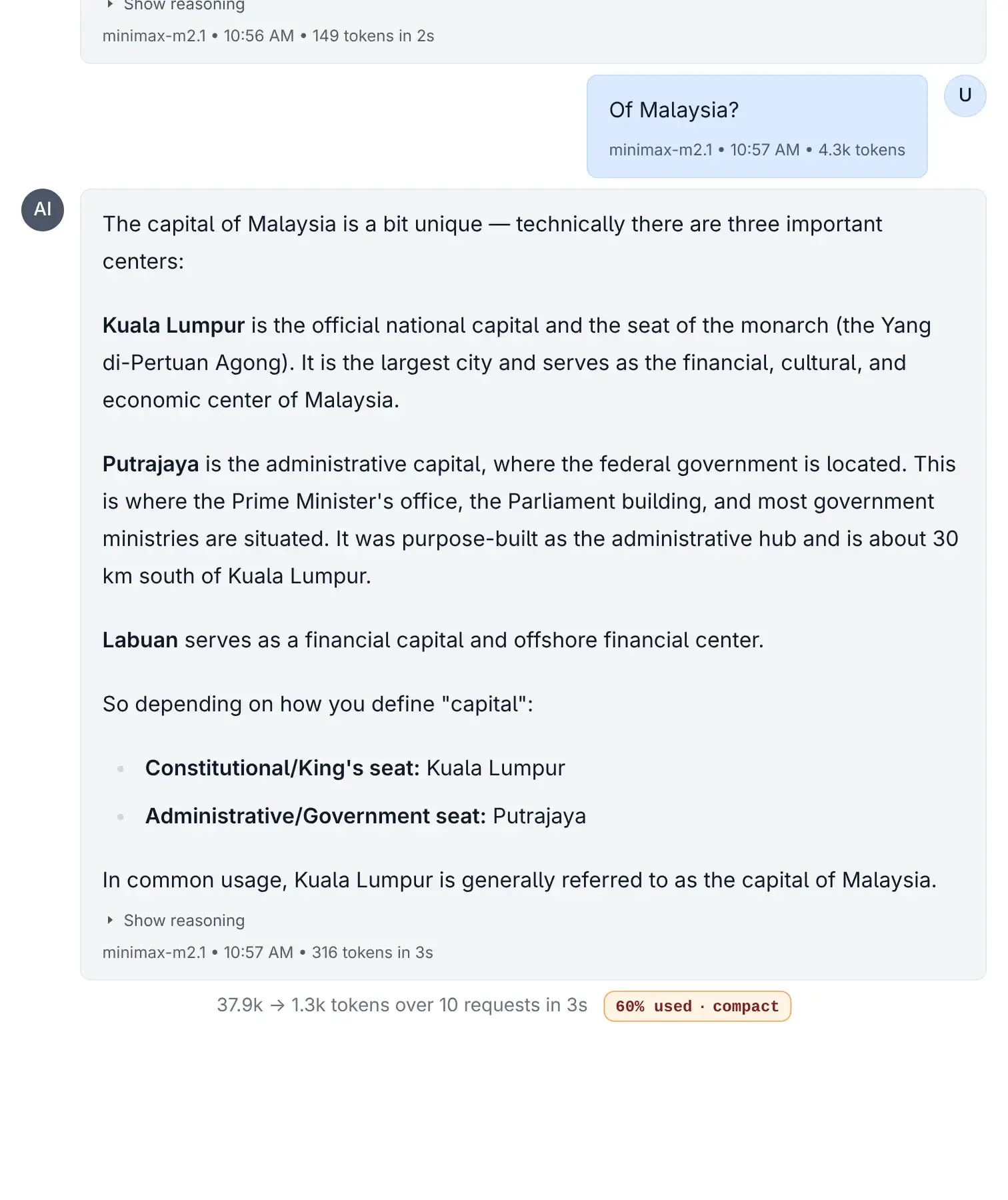
Compact Button Intensity
Click to view full size
What it does
When activated, the Compact feature:
- Analyzes your current conversation thread.
- Creates a new thread with a summarized version of the chat history.
- Preserves key information while discarding redundant or less important details.
- Targets a 30% size of the original context, giving you much more room to continue.
INFO
Benefits
- Save Costs: Reduces the number of tokens sent to the LLM, lowering the cost per request
- Extend Conversations: Frees up context window space, preventing you from hitting the model's hard limit
- Improve Focus: Helps AI focus on the current state of the conversation rather than getting distracted by old history
Customizing Compact Behavior
The Compact feature is fully customizable through your ~/.llms/llms.json configuration file. You can modify the AI model used, the system prompt, and the user message template to tailor the compaction process to your needs.
Configuration Location
Add a compact section to your ~/.llms/llms.json file under the default key:
{
"compact": {
"model": "Gemini 2.5 Flash Lite",
"messages": [
{ "role": "system", "content": "Your system prompt here..." },
{ "role": "user", "content": "Your user message template here..." }
]
}
}Choosing a Model
You can specify any configured model for the compaction task. Fast, cost-effective models like Gemini 2.5 Flash Lite or Claude 3.5 Haiku are good choices since compaction is a straightforward summarization task.
Template Placeholders
The user message template supports the following placeholders that get replaced with the actual thread data:
| Placeholder | Description |
|---|---|
{message_count} | The total number of messages in the conversation being compacted |
{token_count} | The approximate token count of the original conversation |
{target_tokens} | The target token count for the compacted result (default: 30% of original) |
{messages_json} | The full conversation history as a JSON array of message objects |
Example User Message Template
Compact the following conversation while preserving all context needed to
continue it coherently. The conversation has {message_count} messages totaling
approximately {token_count} tokens. Target approximately {target_tokens} tokens.
<conversation>
{messages_json}
</conversation>
Return your response as a JSON object with a single "messages" key containing
the compacted array.Customization Tips
- Adjust the target ratio: Modify the system prompt to request more or less aggressive compaction
- Preserve specific content: Add instructions to always keep certain types of information (code, URLs, decisions)
- Change the output format: Customize how the AI structures the compacted conversation
- Use specialized models: For technical conversations, you might prefer a model with stronger code understanding
🎭 Reasoning Support
Specialized rendering for reasoning models with thinking processes:
Shows:
- Thinking process (collapsed by default)
- Final response
- Clear separation between reasoning and output
📊 Token Metrics
See token usage for every message and conversation:
Displayed metrics:
- Per-message token count
- Thread total tokens
- Input vs output tokens
- Total cost
- Response time
✏️ Edit & Redo
Edit previous messages or retry with different parameters:
- Edit: Modify user messages and rerun
- Redo: Regenerate AI responses
- Hover over messages to see options